 SRE as a Service
SRE as a Service DevOps as a Service
DevOps as a Service DevOps emergency support
DevOps emergency support Kubernetes and cloud migration
Kubernetes and cloud migration Infrastructure & CI/CD audit
Infrastructure & CI/CD audit R&D and technology consulting
R&D and technology consulting Kubernetes support
Kubernetes support Solution for SaaS
Solution for SaaS All services
All services
Kubernetes 1.34’s anticipated release is coming on August 27th. With that around the corner, we’ve prepared a comprehensive run-through of the fascinating 13 alpha features in this release, examining each of them in detail.
From asynchronous API calls and granular container restart rules to native Pod certificates and the new KYAML format, let’s dive into the exciting updates the upcoming K8s version has in store!
Nodes
Add Resource Health Status to the Pod Status for Device Plugin and DRA

Previously, Kubernetes lacked a mechanism for tracking the health of devices allocated to Pods via the Dynamic Resource Allocation (DRA) framework. This rendered troubleshooting significantly more complicated, as it was hard to determine whether a problem was caused by a faulty device (e.g., a GPU or FPGA) or an application error.
This KEP adds a new resourceHealth field to the status section of the Pod specification, providing information on the health of the resources the Pod uses. The resourceHealth field displays one of the following values: Healthy, Unhealthy, or Unknown.
For instance, if a Pod using a GPU enters a CrashLoopBackOff state due to a hardware failure, you can now inspect the Pod’s status using kubectl describe pod to confirm that the GPU device is unhealthy. Alternatively, a controller can detect the unhealthy Pod, delete it, and its ReplicaSet will restart the Pod on another GPU.
Interestingly, this is the third time KEP #4680 is being released as an alpha. Here are the new features being introduced in this version:
- DRA plugins can now report device health to the kubelet through a new gRPC interface (
dra-health/v1alpha1). - kubelet constantly monitors these statuses. If a device fails, kubelet finds all the Pods that are using it.
- The Pod status gets updated with a new
allocatedResourcesStatusfield, showing the real-time state of the Pod’s hardware. This makes the problem visible directly through the Kubernetes API. - The documentation has been updated.
This document provides more details on the implementation design for DRA Pod Device Health.
Container restart rules to customize the pod restart policy
Imagine you’re training an LLM, with hundreds of Pods running on pricey GPUs. They process data in a synchronized fashion, step-by-step, saving their collective progress at each checkpoint.
Suddenly, one of the containers hits a minor snag — a temporary, recoverable error that a simple restart would’ve fixed. Before, Kubernetes (adhering to the Pod’s restartPolicy = Never — a common setting for batch jobs) would have marked the entire Pod as failed. The scheduler would’ve then commenced the expensive, time-consuming process of terminating the Pod and rescheduling it, likely on a whole new node.
Meanwhile, the rest of the Pods sit idle, burning through valuable compute time. The entire fleet is forced to roll back to the last known checkpoint, all waiting for a single Pod to go back online.
KEP-5307 enables more fine-grained control over restarting individual containers within a Pod. Kubernetes can now restart a container in place even if restartPolicy = Never is set for the Pod. This will particularly come in handy in scenarios where recreating and rescheduling a Pod to another node is costly.
To address this, the container specification adds a new restartPolicyRules section featuring a list of rules defining conditions and actions. In the alpha version, the only available condition is the container’s termination code (onExitCodes) and the only action is Restart. The user can specify that, for example, if a container terminates under code 42, it must be restarted immediately (see the example below). If the container terminates under any other code, the standard restart policy defined for the entire Pod will be applied.
Example:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-container
image: nginx:latest
# restartPolicy must be specified to specify restartPolicyRules
restartPolicy: Never
restartPolicyRules:
- action: Restart
when:
exitCodes:
operator: In values: [42]Things to keep in mind: Note that such a container restart will not be considered a Pod failure. Consequently, it will not affect the failure handling policies defined at the higher controller level, for instance, in JobSet (that is, a running Job will not fail). kubelet will be enforcing these rules, ensuring a prompt response right at the node where the Pod is running. Also, the existing exponential backoff mechanism will be used to avoid endless restart cycles caused by repeated failures.
You can enable the new behavior with the ContainerRestartRules feature gate.
Add FileEnvSource and FileKeySelector to add environment generated on the fly
The existing approach to populating environment variables via ConfigMap or Secret is quite tedious. When an initContainer generates a configuration (for example, a temporary access token), that configuration needs to be passed to the main container. The current approach requires creating an additional ConfigMap or Secret object via the API server.
This KEP addresses this issue by allowing an initContainer to write variables to a file within a shared emptyDir volume, which the main container can then read from right during startup, preventing unnecessary API calls. For this, a new fileKeyRef structure is added to the env.valueFrom section in the Pod API (PodSpec).
In the usage example below, the initContainer creates a /data/config.env file containing the variable CONFIG_VAR=hello. The main use-envfile container uses fileKeyRef to read the value of the CONFIG_VAR key from the file and sets it as its CONFIG_VAR environment variable:
apiVersion: v1
kind: Pod
metadata:
name: dapi-test-pod
spec:
initContainers:
- name: setup-envfile
image: registry.k8s.io/busybox
command: ['sh', '-c', 'echo "CONFIG_VAR=HELLO" > /data/config.env']
volumeMounts:
- name: config
mountPath: /data
containers:
- name: use-envfile
image: registry.k8s.io/distroless-app
env:
- name: CONFIG_VAR
valueFrom:
fileKeyRef:
path: config.env
volumeName: config
key: CONFIG_VAR
restartPolicy: Never
volumes:
- name: config
emptyDir: {}Things to keep in mind:
- You will not be able to set one variable by referring to another variable (
VAR1=${VAR2}). - Changing the
fileKeyReffile after the container has been started will not update the environment variables in the container nor trigger a container restart. - Currently, the authors do not plan to support the
envFromanalog for files, i.e., you will have to specify all variables by their names (keys).
Scheduling
Asynchronous API calls during scheduling
The Kubernetes scheduler’s performance is critical. One of its main bottlenecks is synchronous API calls to the kube-apiserver. In other words, the scheduler waits for a call to finish before it can do anything else, which slows the whole process down, especially in large clusters. Some operations, like Pod binding, are already asynchronous, but there hasn’t been a single, unified way to handle all API calls.
This KEP introduces a new universal mechanism inside kube-scheduler to process all API calls asynchronously. It does this via a special component that manages a queue and executes those calls.
This means the scheduler no longer has to wait for API calls to finish. Not only that, but some calls can now be skipped or combined. For example, if a Pod is first marked as unschedulable and then almost immediately gets bound to a node, the call to update the status to unschedulable can be cancelled because it’s already outdated.
The design the authors settled on (illustrated below) is a hybrid approach — a new call queue with a cache acting as a mediator (also see alternative design proposals). A separate component called APIQueue will manage the queue for all asynchronous API calls.
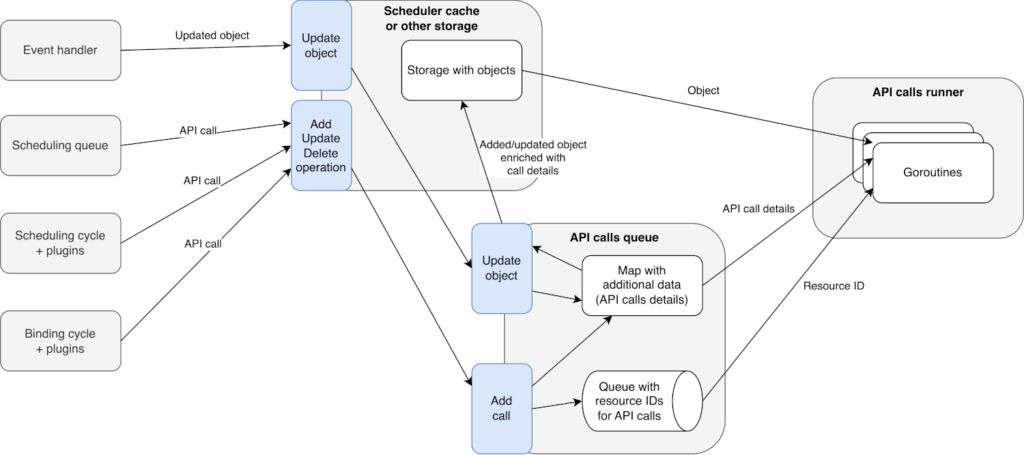
Instead of sending calls directly to the APIQueue, the scheduler’s plugins and internal loops will interact with the scheduler cache. When an API operation occurs, like a Pod status update, it’s first registered in the cache. From that point, the relevant calls are passed to the APIQueue.
The APIQueue will process these calls in the background, so it doesn’t block the main scheduling flow. This way, a Pod can be put back in the scheduling queue even if its unschedulable status hasn’t reached the API yet. Additionally, the APIQueue can merge or cancel operations. For example, it can combine two back-to-back status updates for the same Pod into a single API call.
This new feature can be enabled via the SchedulerAsyncAPICalls feature gate.
Use NominatedNodeName to express the expected pod placement

Pod binding can take a long time — sometimes even minutes. During this entire process, other cluster components don’t know which node the Pod is going to be scheduled to. Without this information, they might take conflicting actions — for example, the Cluster Autoscaler could delete the very node the Pod is about to be placed on. On top of that, the scheduler itself could restart, lose its leader lock, and so on. Since scheduling decisions are only stored in the scheduler’s memory, a new incarnation of it would be oblivious to past decisions and might schedule the Pod on a different node. This would lead to wasted resources and longer delays.
This KEP greatly enhances the NominatedNodeName field in the Pod spec, turning it from a niche preemption indicator into a two-way communication channel between the scheduler and other cluster components. The main goal is to make Pod scheduling more predictable and efficient.
From now on, not only can the scheduler signal its intentions, but external components like Cluster Autoscaler or Karpenter can also influence scheduling decisions.
The scheduler will now set NominatedNodeName at the start of the Pod binding cycle, but only when a Pod needs long-running operations at the Permit or PreBind stages (like provisioning a volume). A new lightweight PreBindPreFlight function has been added to the PreBind plugin interface to check if this is necessary. If all plugins return a Skip status, the scheduler won’t set the NominatedNodeName field.
On the other hand, external components can now officially use NominatedNodeName to give hints to the scheduler. For example, when the Cluster Autoscaler spins up a new node for pending Pods, it can set their NominatedNodeName in advance. When the scheduler picks up such a Pod, it will check if the Pod can be scheduled to the suggested node before checking out other nodes.
A key change in behavior is that the scheduler will no longer clear the NominatedNodeName field if the node is temporarily unavailable or fails to meet the requirements (for instance, if it’s still initializing). This prevents useful hints from the Cluster Autoscaler from being discarded. The component setting the field is now responsible for updating or clearing it.
Finally, to avoid any confusion and keep things clean, the kube-apiserver will automatically clear the NominatedNodeName field once the Pod has been successfully bound. This way, the field will only reflect placement intentions, not the final result.
DRA: Handle extended resource requests via DRA Driver
KEP-5004 bridges the gap between good ol’ Extended Resources and the new, more flexible Dynamic Resource Allocation (DRA) framework. Its main goal is to make the transition to DRA smooth and painless. This new feature ensures full backward compatibility for existing applications, allowing developers and admins to gradually adopt DRA without having to immediately rewrite all their manifests. On top of that, you can now run hybrid clusters where the same hardware uses old device plugins on certain nodes and new DRA drivers on others.
A cluster administrator can now specify the new extendedResourceName field in the DeviceClass spec, assigning it the name of an extended resource, like example.com/gpu. This tells Kubernetes that requests for this resource can be fulfilled using devices managed by DRA.
When a user requests this resource in a Pod spec, the Kubernetes scheduler automatically creates a special ResourceClaim object. This object helps to internally track the allocated resources, sparing the user the requirement to create it manually.
To let the kubelet on the node know which container gets the device, the scheduler writes all the necessary information into the new pod.status.extendedResourceClaimStatus field. This status contains the name of the automatically created ResourceClaim and, more importantly, a precise map that links a specific container and its request to the device allocated to it. Kubelet uses this data to correctly configure and start the container with the proper resources.
Things to keep in mind: Since a device can be requested by the resource claim or the extended resource, the cluster admin must create two quotas with the same limit on one device class to effectively quota the usage of that device class.
For example, if a cluster admin plans to allow 10 example.com/gpu devices in a given namespace, they must create the following:
apiVersion: v1
kind: ResourceQuota
metadata:
name: gpu
spec:
hard:
requests.example.com/gpu: 10
gpu.example.com.deviceclass.resource.k8s.io/devices: 10…provided that the device class gpu.example.com is mapped to the extended resource example.com/gpu.
apiVersion: resource.k8s.io/v1beta1
kind: DeviceClass
metadata:
name: gpu.example.com
spec:
extendedResourceName: example.com/gpuThe Resource Quota controller reconciles the differences (if any) between the usage of the two quotas and ensures their usage is always in sync. To that end, the controller needs permission to list the device classes in the cluster to establish the mapping between device class and extended resource.
DRA: Device Binding Conditions
The regular Kubernetes scheduler assumes that all resources on a node are available at the moment a Pod is bound. However, this isn’t always the case for some devices, such as fabric-attached GPUs that require dynamic attachment via PCIe or CXL switches, and FPGAs that need time-consuming reprogramming before being used. Prematurely binding a Pod to a node before such a device is fully ready leads to Pod startup failures and requires manual intervention.
The new BindingConditions feature addresses this problem by allowing the scheduler to defer the final Pod binding (the PreBind phase) until an external controller confirms that the required resource is ready.
Here’s how it works: a device provider uses the ResourceSlice API to list BindingConditions that must be met for a successful binding. It can also set BindingFailureConditions, which, if triggered, would cancel the binding. Consequently, to avoid getting stuck, there’s a BindingTimeoutSeconds timer that’s used. If the timer runs out before the device is ready, the binding is cancelled, and the Pod goes back into the queue to be rescheduled.
It is the external device controller’s job to update the status of these conditions in the Pod’s ResourceClaim, keeping the scheduler informed of its progress. This way, the scheduler can base its binding decisions on real-time readiness, with no need to know the specifics on how each device is operating.
If device preparation fails, the controller flags the BindingFailureCondition as True. The scheduler then sees this, cancels the binding, releases the resource, and tries to schedule the Pod again, hopefully on another node or via another resource.
Below are a couple of user stories to illustrate the logic behind the new mechanism.
Story 1: Waiting for complex devices. Imagine you are deploying an application that requires a specialized device, such as an FPGA. Before it can be used, the FPGA must be reprogrammed for a specific task, a process that takes several minutes.
Before, the scheduler would have immediately bound the Pod to a node, unaware that the device wasn’t ready. The Pod would’ve started, tried to access the FPGA, crashed, and got stuck in CrashLoopBackOff until the initialization was eventually complete.
Now, the device controller can inform the scheduler, “Hey, the device on this node is currently initializing.” Upon seeing that, the scheduler won’t rush ahead with the binding. Instead, it waits for the process to complete. If the initialization is successful, the scheduler receives the OK and binds the Pod to the node. On the other hand, if the process fails, the controller reports the failure, and the scheduler cancels its placement decision to schedule the Pod elsewhere.
Story 2: Attaching resources on demand. In this scenario, the user requests a GPU for their Pod. However, this GPU is part of a shared resource pool and must be dynamically attached to a node via a high-speed PCIe fabric on demand.
Before, the scheduler considered a node without a physically installed GPU to be simply a node lacking a GPU. It could not know a resource could be attached on the fly, let alone count on it in making a decision. Such a Pod would never end on that node.
Now, a specialized controller can inform the scheduler, “Hey, I have free GPUs; I can attach one to this node, but I need time.” When a user requests such a GPU, the scheduler first selects a suitable node and “reserves” it while deferring Pod binding. It then tells the controller to proceed with the attachment. As soon as the controller successfully attaches the GPU to the node and reports that it’s ready, the scheduler binds the Pod. If the attachment fails for any reason, the scheduler cancels its placement choice and starts seeking other options.
Things to keep in mind:
- The maximum number of
BindingConditionsandBindingFailureConditionsper device is limited to 4. This ensures the scheduler can evaluate the conditions without excessive overhead, and theResourceSlicesize is not too large. - To ensure reliable scheduling, external controllers must update
BindingConditionspromptly and correctly. Any delays or errors they commit will directly compromise scheduling stability.
DRA: Consumable Capacity
Previously, you could only share a device if multiple Pods or containers pointed to the single ResourceClaim that had it allocated. KEP-5075 changes this by allowing independent ResourceClaims to get shares of the same underlying device. This way, you can share resources across completely unrelated Pods, even if they belong to different namespaces.
With this new mechanism, a device can declare that it allows multiple allocations using the allowMultipleAllocations field in the ResourceSlice’s devices section. Users can also request a certain “capacity” from a shareable device with the new CapacityRequests field in their ResourceClaim.
Based on these requests and the device’s own sharing policy, the Kubernetes scheduler will calculate the actual consumed capacity (which might be rounded to the nearest valid value). The result of the allocation, including the capacity consumed, is then reflected in the ConsumedCapacities field of the allocation result (DeviceRequestAllocationResult), and a unique ShareID is assigned to each share.
Example:
kind: ResourceSlice
...
spec:
driver: guaranteed-cni.dra.networking.x-k8s.io
devices:
- name: eth1
basic:
allowMultipleAllocations: true # New KEP's key field. Thanks to it, the scheduler knows that the eth1 device can be allocated to multiple independent ResourceClaims at the same time.
attributes:
name:
string: "eth1"
capacity:
bandwidth:
sharingPolicy: # Defines the bandwidth resource sharing policy.
default: "1Mi"
validRange:
minimum: "1Mi"
chunkSize: "8"
value: "10Gi"Part of the grounds for this KEP are scenarios that require the allocation of virtual network devices (e.g., in the CNI DRA driver) between multiple Pods, or allocation of virtual GPU memory shares on AWS devices. In those cases, traditional partitioning into predefined static partitions is impractical.
On top of that, KEP provides a DistinctAttribute mechanism to ensure that if a user requests multiple identical resources, they are allocated from different physical devices rather than the same one. This prevents situations where, for example, two requested NICs turn out to be parts of the same physical device when, in fact, separate physical entities are required.
Network
Relaxed validation for Services names
Currently, Service names in Kubernetes adhere to more restrictive validation rules (as defined in RFC 1035) compared to most other Kubernetes resources (which follow RFC 1123). KEP-5311 relaxes the validation rules for Service object names, aligning them with the standard applied to the majority of other resources.
You can activate this new behavior via the RelaxedServiceNameValidation feature gate (disabled by default). When the feature gate is enabled, new Service objects are validated against the new, less strict rules (NameIsDNSLabel). Consequently, the validation for the service name field within Ingress resources (spec.rules[].http.paths[].backend.service.name) is relaxed as well.
Things to keep in mind: When updating existing Services, their names are not re-validated, as the metadata.name field is immutable. This prevents issues with the existing resources from popping up should you disable the feature gate at a later time.
Allows setting any FQDN as the pod’s hostname
This KEP gives Kubernetes users full control over the hostname within the Pod, allowing them to set any arbitrary fully qualified domain name (FQDN).
By default, a Pod’s hostname is simply its metadata.name (e.g., my-cool-pod-12345). This is a short domain name, not an FQDN. While Kubernetes does have pod.spec.hostname and pod.spec.subdomain fields that let you build an FQDN, it is always tied to the cluster’s internal DNS. For example, if you set hostname: "foo" and subdomain: "bar", you’ll get an FQDN like foo.bar.my-namespace.svc.cluster.local.
However, there is currently no way to tell a Pod, “Hey, your hostname will be database.my-company.com.” Many legacy or complex applications (like some databases or identity management systems, such as FreeIPA) expect the OS they run on to have a specific, predefined FQDN. In its current implementation, Kubernetes automatically adds a cluster suffix (like .default.pod.cluster.local) to the Pod’s name, which breaks these applications because the expected and actual FQDNs are a mismatch.
This KEP introduces a new hostnameOverride field in PodSpec. If this field is set, its value will be used as the Pod’s hostname, overriding the current hostname, subdomain, and setHostnameAsFQDN fields. The specified FQDN will be written to the container’s /etc/hosts file, allowing the application to identify itself correctly. You can enable this new behavior via the HostnameOverride feature gate.
Things to keep in mind:
- This feature only changes the hostname inside the Pod — the value that the
hostnameandhostname -fcommands return. It doesn’t create any corresponding DNS records in the cluster DNS. As a result, other Pods won’t be able to resolve this FQDN to the Pod’s IP address unless you configure the DNS manually. - The hostname cannot be any longer than 64 bytes, which is a Linux kernel limitation. API validation will be added to prevent Pods with longer names from being created.
- You cannot use the
hostnameOverrideandsetHostnameAsFQDN: truetogether, as they do opposite things. The API will reject such configurations with an error stating the fields are mutually exclusive. If you really want to better understand the logic of how and when the new feature works, check out the table in the KEP’s Design Details section. - Lastly, if a Pod has
hostNetwork: trueset, it will still use its host node’s hostname, and thehostnameOverridefield will be ignored.
Auth
Pod Certificates
KEP-4317 lets you natively propagate X.509 certificates to workloads in your cluster. The problem is, while the certificates.k8s.io API provides a flexible way to request certificates, their delivery and management within workloads had to be handled by developers and cluster administrators.
The authors implement a new type of API resource called PodCertificateRequest (a narrowed-down version of CertificateSigningRequest). This resource allows a Pod to directly request a certificate from a particular signer and include all the necessary information on its identity in the request. A new source for projected volumes, PodCertificate, is also a part of this KEP. With this volume mounted in a Pod, kubelet can do a complete credential management cycle: generate a private key, create a PodCertificateRequest, wait for the certificate to be issued, and mount the key and certificate chain into the Pod’s file system.
As a primary use of this mechanism, KEP allows Pods to authenticate to a kube-apiserver via mTLS, which is a more secure alternative to service account tokens. A new X.509 extension called PodIdentity embeds Pod information into the certificate, including its UID, namespace, and the host it’s running on. Kube-apiserver, in turn, recognizes and validates those certificates by mapping them to specific Pods.
For developers, using this feature boils down to adding a podCertificate source and signerName (e.g., the newly built-in kubernetes.io/kube-apiserver-client-pod) to the Pod specs — see the example below.
Example:
apiVersion: v1
kind: Pod
metadata:
namespace: default
name: pod-certificates-example
spec:
restartPolicy: OnFailure
automountServiceAccountToken: false # We don't want the Pod to use bearer tokens
containers:
- name: main
image: debian
command: ['sleep', 'infinity']
volumeMounts:
- name: kube-apiserver-client-certificate
mountPath: /var/run/secrets/kubernetes.io/serviceaccount
volumes:
- name: kube-apiserver-client-certificate
projected:
sources:
- podCertificate: # The new source
signerName: "kubernetes.io/kube-apiserver-client-pod"
credentialBundlePath: credentialbundle.pem # File with the certificate
- configMap:
localObjectReference: kube-root-ca.crt
items:
- key: ca.crt
path: kube-apiserver-root-certificate.pem
- downwardAPI:
items:
- path: namespace
fieldRef:
apiVersion: v1
fieldPath: metadata.namespaceAdd PSA to block setting .host field from ProbeHandler and LifecycleHandler
The Host field in the ProbeHandler and LifecycleHandler structures allows the users to specify their own host for TCP and HTTP probes, evoking the risk of server-side request forgery (SSRF) attacks since kubelet can be directed to any IP address.
The KEP adds a new Pod Security Admission (PSA) policy, enabling cluster administrators to prohibit the creation of Pods that use the Host field. This new policy will be a part of the default Baseline security profile, rendering it easier to enforce. Removing the Host field from the API would break backward compatibility, so there are no plans to do so.
CLI
KYAML
Good news: Norway is finally safe thanks to the all-new KYAML — a “dialect” of YAML that the existing K8s ecosystem is fully capable of parsing.

While YAML is easy to read, it comes with several notable drawbacks. For instance, its reliance on whitespace indentation requires users to meticulously track nesting depth. Furthermore, as quotes around strings are generally optional in YAML, certain string values are automatically converted to other data types.
For example, without quotes, NO, no, N, YES, yes, Y, On, and Off are parsed as booleans (oh, the famous “Norway problem”). Values like _42 and _4_2_ are parsed as numbers, while a string such as 1:22:33 is converted to a base-60 number. This is convenient for calculating seconds, but the problem is that the spec’s authors forgot to set a maximum for these sexagesimal digits. As a result, if you enter six numbers separated by colons, like a MAC address, they’ll be parsed as a very large time interval instead of a string.
KYAML solves the aforementioned problems as follows:
- All strings are always enclosed in quotes to avoid accidental type conversion (e.g., “no” won’t be converted to
false). - It explicitly uses the “flow-style” syntax:
[]for lists and{}for maps. - Reduced sensitivity to whitespace and indentation renders it more robust and error-proof.
Crucially, KYAML is still a valid YAML, which makes it compatible with all existing tooling (e.g., any YAML processor can read it).
In the long run, the proposal is to make KYAML the standard for all documentation and examples in the Kubernetes project. This should push the ecosystem toward using safer, more error-resistant practices when working with configurations.
Of course, you’re eager to see an example:
$ kubectl get -o kyaml svc hostnames
---
{
apiVersion: "v1",
kind: "Service",
metadata: {
creationTimestamp: "2025-05-09T21:14:40Z",
labels: {
app: "hostnames",
},
name: "hostnames",
namespace: "default",
resourceVersion: "37697",
uid: "7aad616c-1686-4231-b32e-5ec68a738bba",
},
spec: {
clusterIP: "10.0.162.160",
clusterIPs: [
"10.0.162.160",
],
internalTrafficPolicy: "Cluster",
ipFamilies: [
"IPv4",
],
ipFamilyPolicy: "SingleStack",
ports: [{
port: 80,
protocol: "TCP",
targetPort: 9376,
}],
selector: {
app: "hostnames",
},
sessionAffinity: "None",
type: "ClusterIP",
},
status: {
loadBalancer: {},
},
}Sleek, isn’t it? Community has mixed emotions about KYAML, though.
Conclusion
As the upcoming 1.34 release demonstrates, Kubernetes is constantly evolving, with each subsequent version introducing powerful new capabilities. We’ve explored a bunch of alpha features, from fine-grained container restart policies to the robust new KYAML format. The complete list of changes coming to the next Kubernetes release (not just alpha covered by this overview) can be found in the 1.34 Enhancements Tracking project table on GitHub.
Which of those are you most excited to experiment with? Share your thoughts in the comments below!

Comments